Our heavyweight helicopter equal in the world does not have
In Rostov started production of the most load-lifting rotary-wing car The Russian holding «Helicopt[...]

Everything about aircrafts and helicopters. News and events in aviation worldwide. Civil, transportation, military helicopters and airplanes.

Everything about aircrafts and helicopters. News and events in aviation worldwide. Civil, transportation, military helicopters and airplanes.

Everything about aircrafts and helicopters. News and events in aviation worldwide. Civil, transportation, military helicopters and airplanes.

Everything about aircrafts and helicopters. News and events in aviation worldwide. Civil, transportation, military helicopters and airplanes.




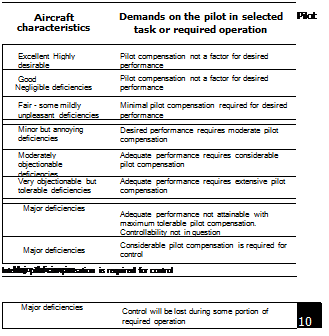
Figure 7.2 illustrates the decision tree format of the Cooper-Harper handling qualities rating scale. Test pilots and flying qualities engineers need to be intimately familiar with its format, its intended uses and potential misuses. Before we begin a discussion on the rating scale, we refer the reader back to Fig. 7.1 and to the key influences on control strategy which should be reflected in pilot opinion; we could look even further back to Fig. 6.1, highlighting the internal attributes and external factors as influences on flying qualities. The pilot judges quality in terms of his or her ability to perform a task, usually requiring closed-loop control action. A key point in both figures is that the handling qualities and pilot control strategy are a result of the combined quality of the aircraft characteristics and the task cues. The same aircraft can be Level 1 flying routine operations at day and then Level 3 at night, or when the wind blows hard, or when the pilot tries to accomplish a landing in a confined area. An aircraft may be improved from Level 3 to 2 by providing the pilot with a night vision aid or from Level 2 to 1 by including appropriate symbology on a helmet-mounted display. Handling qualities are task dependent and that includes the natural environmental conditions in which the task is to be performed, and the pilot will be rating the situation as much as the aircraft. We will discuss the scale and HQRs in the form of a set of rules of thumb for their application.
 |
|
|
|
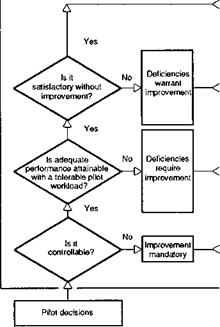
(1) Follow the decision tree from left to right. Pilots should arrive at their ratings by working through the decision tree systematically. This is rule number 1 because it helps the pilot to address the critical issue of whether the aircraft is Level 1, 2 or 3 in the intended task or subtask. The decision tree solicits from the pilot his opinion of the aircraft’s ability to achieve defined performance levels at perceived levels of workload.
(2) An HQR is a summary of pilot subjective opinion on the workload required to fly a task with a defined level of performance. An HQR can be meaningless without back-up pilot comment. It is the recorded pilot opinion which will be used to make technical decisions, not the HQR, because the HQR does not tell the engineer or his manager what the problems are. Often a structured approach to qualitative assessment will draw on a questionnaire that ensures that all the subject pilots address at least a common set of issues. We will consider the ingredients of a questionnaire in more detail later.
(3) Pilot HQRs should be a reflection of an aircraft’s ability to perform an operational role. The MTEs should be designed with realistic performance requirements and realistic task constraints. The pilot then needs to base his rating on his judgement of how an ‘average’ pilot with normal additional tactical duties could be expected to perform in a similar real-world task.
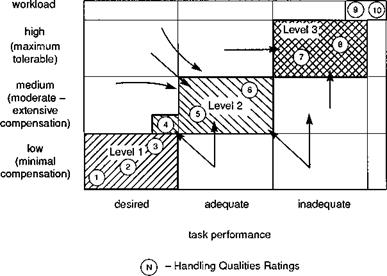
(4) Task performance and workload come together to make up the rating, but workload should be the driver. This is most important. To highlight the emphasis we refer to Fig. 7.3 where workload and task performance are shown as two dimensions in the piloting trade-off. Task performance is shown in three categories – desired, adequate and inadequate. Workload is also shown in three categories – low, moderate to extensive and maximum tolerable, reflecting the rating scale parlance. HQRs on the Cooper – Harper scale fall into the areas shown shaded. Figure 7.3 acknowledges that a pilot may be able to work very hard (e. g., using maximum tolerable
|
Fig. 7.3 The contributions of workload and task performance to the HQR |
compensation) and achieve desired performance, but it is not appropriate then to return a Level 1 rating. Instead, he should aim for adequate performance with some spare workload capacity. Similarly, a pilot should not be satisfied with achieving adequate performance at low workload; he should strive to do better. A common target for pilots in this situation would be to try to achieve desired performance at the lower end of Level 2, i. e., HQR 4. Level 1 characteristics should be reserved for the very best, those aircraft that are fit for operational service. An HQR 4 means that the aircraft is almost good enough, but deficiencies still warrant improvement.
(5) Two wrongs can make a disaster. Handling qualities experiments often focus on one response axis at a time, two at the most. We have seen in Chapter 6 how much it takes to be a Level 1 helicopter, and a question often arises as to how much one or two deficiencies, among other superb qualities, can degrade an aircraft. The answer is that any Level 2 or 3 deficiency will degrade the whole vehicle. A second point is that several Level 2 deficiencies can accumulate into a Level 3 aircraft. Unfortunately, there seems to be very little rotorcraft data on this topic, but Hoh has given a hint of the potential degradations in the advisory ‘product rule’ (Ref. 7.5)
_1(m+1) m
Rm = 10 + Ri – 10) (7Л)
where Rm is the predicted overall rating and Ri are the predicted ratings in the individual m axes. According to the above, two individual HQR 5s would lead to a multi-axis rating of 7. The fragile nature of such prediction algorithms emphasizes the critical role of the pilot in judging overall handling qualities and the importance of tasks that properly exercise the aircraft in its multi-axis roles. So while sidesteps and quickhops might be appropriate MTEs for establishing roll and pitch control power requirements, the evaluations should culminate with tasks that require the pilot to check the harmony when flying a mixed roll-pitch manoeuvre. Ultimately, the combined handling should be evaluated in real missions with the attendant mission duties, before being passed as fit for duty.
(6) The HQR scale is an ordinal one, and the intervals are far from uniform. For
example, a pilot returning an HQR of 6 is not necessarily working twice as hard as when he returns an HQR of 3; Cooper and Harper, in discussing this topic, suggest that ‘… the change in pilot rating per unit quality should be the same throughout the rating scale’. The implied workload nonlinearity has not hindered the almost universal practice of averaging ratings and analysing their statistical significance. Many examples in this book present HQRs with a mean and outer ratings shown, so the author clearly supports simple arithmetic operations with HQRs. However, this practice should be undertaken with great care, particularly paying attention to the extent of the rating spread. If this is large, with ratings for one configuration appearing in all three levels for example, then averaging would seem to be inappropriate. If the rating spread is only 1 or 2 points, then it is likely that the pilots are ‘experiencing’ the same handling qualities. Of course, if the ratings still cross a boundary, and the mean value works out at close to 3.5 or 6.5, then it may be necessary to put more pilots through the evaluation or explore some task variations. The whole issue of averaging, which can make data presentation so appealing, has to be undertaken in the light of the pilots’ subjective comments. Clearly, it would be
inappropriate to average a group of ratings when the perceived handling deficiencies recorded in each of the pilot’s notes were different.
(7) Are non-whole ratings legal? There appears to be universal agreement that pilots should not give ratings of 3.5 or 6.5; there is no space here to sit on the fence and the trial engineer should always reinforce this point. Beyond this restriction, there seems to be no good reason to limit pilots to the whole numbers, provided they can explain why they need to award ratings at the finer detail. A good example is the ‘distance’ between HQR 4 and 5. It is one of the most important in the rating scale and pilots should be particularly careful not to get stuck in the handling qualities ‘potential well’ syndrome of the HQR 4. In many ways the step from HQR 4 to HQR 5 is a bigger workload step than from 3 to 4 and pilots may feel the need to return HQRs between 4 and 5; equally, pilots may prefer to distinguish between good and very good configurations in the region between HQR 2 and 3.
(8) How many pilots make a good rating? This question is always raised when designing a handling qualities experiment. The obvious trade-off involving the data value is expressed in terms of authenticity versus economy. Three pilots seems to be the bare minimum with four or five likely to lead to a more reliable result and six being optimal for establishing confidence in the average HQR (Ref. 7.6). For a well-designed handling qualities experiment, there will inevitably be variations in pilot ratings as a result of different pilot backgrounds, skill level, pilots’ perception of cues, their natural piloting techniques and standards to which they are accustomed (e. g., one pilot’s HQR 4 might be another’s 5). Measuring this ‘scatter’ is an important part of the process of understanding how well the aircraft will work in practice. But if the scatter is greater than about two ratings, the engineer may need to consider redesigning the experiment.
(9) How to know when things are going wrong. A wide variation of ratings for the same MTE should ring alarm bells for the trial engineer. There are many legitimate reasons for a spread in HQRs but also some illegitimate ones. One reason could be that the pilots are not flying the same task. Part of the task definition are the standards for desired and adequate performance. These will be based on some realistic scenario, e. g., sidestep from one cover point to another, 100 m distant, and establish a hover within a defined world-referenced box, with permitted errors up to, say, 2 m. The task definition might also add that the pilot should maintain his flight path below 10 m above the ground and accomplish the task in a defined time. The more detail that is added to the task definition, the more likely it is that each pilot will try to fly the same MTE and the more the HQR scatter will be left to pilot differences, which is what is required. Conversely, the less detail there is, the more likely is the chance of different pilots interpreting the task differently; one may fly the task in 15 s, another in 20 s and the different demands will drive the workload and hence ratings. Next to the need for complete and coherent task definition comes the need to provide the pilot with sufficient cues to enable him to judge his task performance. This is a critical issue. In real-world scenarios, pilots will judge their own task performance requirements and they will usually do this on the basis of requiring low to moderate pilot compensation. Pilots do not usually choose to fly at high levels of workload, unless they have to, and will normally set performance requirements based on task cues that they can clearly perceive. Unless a pilot has made an error of judgement, he or she will not normally fly into a condition where the task cues are insufficient for guidance and stabilization. In clinical flying
|
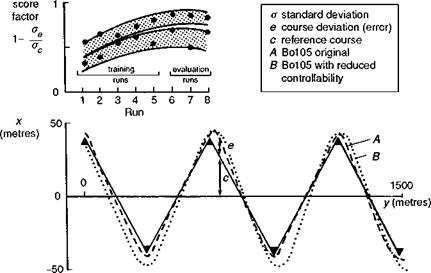
Fig. 7.4 The DLR score factor (Ref. 7.7) |
qualities tests, it is important for the trials engineer to work closely with the ‘work-up’ pilot to define realistic performance goals that an average pilot would be expected to perceive in operations. Then, when the pilot returns an HQR, the actual task performance achieved should correlate well with that perceived by the pilot. Unless properly addressed, this issue can devalue results of handling qualities experiments. A third factor in HQR scatter deserves a rule all on its own.
(10) How long before a pilot is ready to give a rating? There is no simple answer to this question, but pilots and engineers should be sensitive to the effects of learning with a new configuration. Briefly, pilots should be allowed enough time to familiarize with a configuration, for general flying and in the test MTEs, before they are ready to fly the evaluation runs. The DLR test technique, adopted during in-flight simulation trials, involves computing the ‘score factor’ of the MTE, i. e., the ratio of successive performance measures (Fig. 7.4, Ref. 7.7). When the score factor rises above a pre-defined level, then the pilot is at least achieving repeatable task performance, if not workload. Ultimately, the pilot should judge when he is ready to give a formal evaluation and the trial engineer should resist forcing a ‘half-baked’ HQR. Something for both the test pilot and the engineer to bear in mind is that the subjective comments recorded during the learning phase are very important for understanding the basis for the eventual HQR; a communicative pilot will usually have a lot of very useful things to say at this stage. This brings us to the subject of communication between the pilot and engineer and flying qualities jargon.
(11) Interpreting test pilot talk. In handling qualities evaluations, test pilots will use a variety of descriptors within their subjective comment to explain the impact of good and bad characteristics. To simplify this discussion, we will relate two categories – the classical pilot qualitative language, e. g., sluggish, crisp, smooth and predictable, and the engineering parlance, e. g., control power, damping and bandwidth. HQRs are the summary of pilot comment, and it is important that the pilot comment is consistent and understandable; once again, it is the pilot comment that directs the engineer towards improvement. Two observations on pilot comment are worth highlighting here. First, any classical parlance should be defined in terms relating to task; e. g., the roll response of this aircraft is sluggish because it takes too long to achieve the required bank angle. There is no universal dictionary for classical parlance so it is a good idea to establish agreed meanings early in a trial; the HQRs will then be more valuable. Second, it is the author’s considered opinion that test pilots should be strongly discouraged from using engineering parlance during evaluations, unless they are conversant with the engineering background. Sometimes quite different engineering parameters can lead to similar effects and if pilots try to associate effects with causes, they run the risk of making predictive judgements based on what they think will be the case. Engineers need test pilots to tell them what aspects are good or bad and not try to diagnose why. Ironically, it is the very skill that test pilots are valued for – the ability to think about and interpret their response – that can spoil their ratings. When it comes to the evaluation, deeply learned and instinctive skills are being exercised and, to an extent, thinking can intrude on this process. It is far better for test pilots to describe their workload in terms that are subjective but unambiguous.
(12) When is an HQR not an HQR? During the assembly of a handling qualities database, configurations will be evaluated that span the range from good to bad, and pilots need not think that it is their fault if they cannot achieve the performance targets. During the development of a new product, flying qualities deficiencies may appear and the test pilots need to present their findings in a detached manner. Above all, test pilots that participate in such evaluations need to be free from commercial constraints or programme commitments that might influence their ratings. This point is stressed by Hoh in Ref. 7.8. Eventually it will be in both the user’s and manufacturer’s interest to establish the best level of flying quality.
(13) Pilot fatigue – when does an HQR lose its freshness? This will certainly vary from pilot to pilot and task to task, but evaluation periods between 45 and 90 min seem from experience to cover an acceptable range. The pilot fatigue level, and to an extent this can be influenced by their attitude to the evaluation, can be a primary cause for spread in HQRs. The pilot is usually the best judge of when his performance is being impaired by fatigue, but a useful practice is to introduce a reference configuration into the test matrix on occasions as a means of pilot calibration.
(14) HQRs are absolute, not relative. This is an important rule, but perhaps the most difficult to apply or live by, especially if several different aircraft are being compared in an experiment; there will always be the temptation for the pilot to compare an aircraft or configuration with another that has already achieved a particular standard and been awarded a rating. Disciplined use of the Cooper-Harper decision tree should help the pilots resist this temptation, and appropriate training and good early practice would seem to be the best preventative medicine for this particular bad habit.
(15) The HQR is for the aircraft, not for the pilot. Piloting workload determines the rating but the rating needs to be attributed to characteristics of the aircraft and task cues as defined in the Cooper-Harper rating scale. Emphasis on HQR, rather than pilot rating, can help with this important distinction.
(16) An HQR does not tell the whole story. In this last point we reiterate rule number 2 that every HQR should be accompanied by a sheet of pilot comments to give the full story. This can often be derived as a series of answers on a questionnaire addressing the various aspects covered in the Cooper-Harper decision tree – vehicle characteristics, workload (compensation) and task performance; task cues also need to be addressed, and the absence of any reference to task cues in the Cooper-Harper decision tree is explained by the assumption that sufficient task cues exist for flying the task. The subject of task cues and the need for pilot subjective impressions of the quality of task cues have received more prominence with the introduction of vision aids to support flying at night and in poor weather. This topic is addressed further in Section 7.3.3.
These 16 rules represent this flying qualities engineer’s assessment of the important facets of the subjective measurement scale and the HQR. Put together, the issues raised above highlight the importance of the special skills required of test pilots, enhanced by extensive training programmes. To examine how these work in practice, we need to discuss the design, conduct and test results from handling qualities evaluations.