
Our heavyweight helicopter equal in the world does not have
In Rostov started production of the most load-lifting rotary-wing car The Russian holding «Helicopt[...]

Everything about aircrafts and helicopters. News and events in aviation worldwide. Civil, transportation, military helicopters and airplanes.

Everything about aircrafts and helicopters. News and events in aviation worldwide. Civil, transportation, military helicopters and airplanes.

Everything about aircrafts and helicopters. News and events in aviation worldwide. Civil, transportation, military helicopters and airplanes.

Everything about aircrafts and helicopters. News and events in aviation worldwide. Civil, transportation, military helicopters and airplanes.




The mean squared error (MSE) of an estimator of a parameter is the expected value of the square of the difference between the estimator and the parameter. It is given as MSE(p) = E{(P — P)2}. It measures how far the estimator is off from the true value on the average in repeated experiments.
B17 MEDIAN AND MODE
The median is a middle value: the smallest number such that at least half the numbers are no greater than it. If the values have an odd number of entries, the median is the middle entry after sorting the values in an increasing order. If the values have an even number of entries, the median is the smaller of the two middle numbers after sorting. The mode is a most common or frequent value. There could be more than one mode. It is a relative maximum. In estimation, data affected by random noise are used, and the estimate of the parameter vector is some measure or quantity related to the probability distribution; it could be mode, median, or mean of the distribution. The mode defines the value of x for which the probability of observing the random variable is a maximum. Thus, the mode signifies the argument that gives the maximum of the probability distribution.
One must be able to identify the coefficients/parameters of the postulated mathematical model (Chapters 2 and 9), from the given I/O data of a system under experiment (with some statistical assumptions on the noise processes, which contaminate the measurements). Identifiability refers to this aspect. The input to the system should be persistently exciting. The spectrum of the input signal should be broader than the bandwidth of the system that generates the data.
B15 INFORMATION MEASURE
The concept of information measure is of a technical nature and does not directly equate to the usual emotive meaning of information. The entropy, somewhat directly related to dispersion, covariance, or uncertainty, of a random variable x (with probability density p(x)) is defined as
Hx = Ex{logp(x)}, where E is the expectation operator.
ForGaussianm vectorx, itisgivenasHx = 1/2m(log2 pi + 1) + 1/2log|P|; pi = p, with P as the covariance matrix of x. Entropy is thought of as a measure of disorder or lack of information. Let Hp = —Epilogp(p)], the entropy prior to collecting data z, and p(b) the prior density function of b. When data are collected we have Hp/z = — Ep/z{logp(b|z)}. Then, the measure of the average amount of information provided by the experiment with data z and parameter b is given by I = Hp — Ez{Hp/z}. This is ‘‘mean information’’ in z about p. The entropy is the dispersion or covariance of the density function and hence the uncertainty. Thus, the information is seen as the difference between the prior uncertainty and the ‘‘expected’’ posterior uncertainty. Due to collection of data z, the uncertainty is reduced and hence the information is gained. The information is a non-negative measure and it is zero if p(z, P) = p(z) • p(P); i. e., if the data is independent of the parameters.
For xj and x2, the normally distributed random variables with arbitrary means and variances as sj and s2, the following variances are defined:
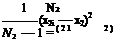 1 N
1 N
N — 1Y1(xu — Xl)2 and -2
With sj and s2 the unbiased estimates of the variances, and x1; and x2i the samples from the Gaussian distribution, we have x2 = (N1s21)-1 and x2 = (N2s21)-2 as the x distributed variables with DOF h1 = N1 — 1 and h2 = N2 — 1. The ratio defined as F = (fy is described by F-distribution with (h1, h2) degrees of freedom.
The F-distribution is used in F-test, which provides a measure for the probability that the two independent samples of variables of sizes n1 and n2 have the same variance.
S2
The ratio t = -1 follows F-distribution with h1 and h2 DOF. The test hypotheses are
S2
formulated and tested for making decisions on the (unknown!) truth:
H1(s > s2): t > F1—„ H2(s2 < s2): t < Fa
at the level of 1 — a or a. The F-test is useful in determining a proper order or structure in
If bi and b2 are the unbiased estimates of the parameter vector b, then compare these estimates in terms of error covariance matrices: E{(b — b>1)(b — Ьі)Г} < E{ (b — b2)(b — b2)T}. The estimator /31 is said to be superior to b2 if the inequality is satisfied. If it is satisfied for any other unbiased estimator, then we get the efficient estimator. The mean square error and the variance are identical for unbiased
estimators and such optimal estimators are minimum variance unbiased estimators. The efficiency of an estimator can be defined in terms of Cramer-Rao inequality (Chapter 9). It gives a theoretical limit to the achievable accuracy, irrespective of the estimator used: F{[/3(z) — bl [b(z) — bl^} > Im4b), the matrix Im is the Fisher information matrix, and its inverse is a theoretical covariance limit. If it is assumed that the estimator is unbiased, then such an estimator with equality valid is called an efficient estimator. The Cramer-Rao inequality means that for an unbiased estimator, the variance of parameter estimates cannot be lower than its theoretical bound Im1(b). The Cramer-Rao bounds define uncertainty levels around the estimates obtained by using the maximum likelihood/output error method (Chapter 9).
Two events are independent if the occurrence of one event gives no information about the occurrence of the other event. The two events, A and B, are independent if the probability that they both occur is equal to the product of the probabilities of the two individual events: P(A, B) = P(A)P(B). Two events are disjoint or mutually exclusive if the occurrence of one is incompatible with the occurrence of the other, i. e., if they cannot both happen at once (if they have no outcome in common). Equivalently, two events are disjoint if their intersection is the empty set.
B11 EXPECTATION
The expected value of a random variable is the long-term average of its values. For a discrete random variable (one that has a countable number of possible values), the expected value is the weighted average of its possible values, and the weight assigned to each possible value is the chance/probability that the random variable takes that value. The mathematical expectation E(x) = ^”= 1 x, P(x = x,) and E(x) = J1 xp(x)dx with P as the probability distribution of variables x and p the PDF of variable x. It is a weighted mean and the weights are individual probabilities. The expected value of the sum of two variable is the sum of their expected values E(X + Y) = E(X) + E( Y), similarly E(a x X) = a x E(X).
The distribution of a set of numerical values shows how they are distributed over real numbers and it is completely characterized by the empirical distribution function. The probability distribution of a random variable is defined by its probability distribution function (PDF). For each real value of x, the cumulative distribution function of a set of numerical data is the fraction of observations that are less than or equal to x, and a plot of the empirical distribution function is an uneven set of stairs, with the width of the stairs as the spacing between adjacent data. The height of the stairs depends on how many data points have exactly the same value. The distribution function is zero for small enough (negative) values of x, unity for large enough values of x, and increases monotonically. If y > x, the empirical distribution function evaluated at y is at least as large as the empirical distribution function evaluated at x.
It gives the degree of correlation between two random variables. It is given as Pij = COJ(j’j ; — 1 — Pij — 1 • Pij = 0 for independent variables xt and xj, and for definitely correlated processes p = 1j. If a variable d is dependent on many x;, then the correlation coefficient for each of xi can be utilized to determine the degree of this correlation with d as
![]() E (d(k) — d)(xi(k) — xi) k=1_
E (d(k) — d)(xi(k) — xi) k=1_
NN
4 E (d(k) — d)ME (xi(k) — x,)2 У k=1 У k=1
The ‘‘under bar’’ represents the mean of the variable. If |p(d, x;)| approaches unity, then d can be considered linearly related to particular x,. The covariance between two variables is defined as
Cov(xi, xj) = E{ [x, — E(x,)] [xj — E(xj)] }
By definition, the covariance matrix should be symmetric and positive semidefinite. It gives theoretical prediction of the state-error variance. If the parameters are used as variables in the definition, it gives the parameter estimation error covariance matrix. The square roots of the diagonal elements of this matrix give standard deviations of the errors in estimation of states or parameters, as the case may be. It is emphasized that the inverse of the covariance matrix is the indication of the information content
in the signals about the parameters or states. Large covariance signifies higher uncertainty and low information and low confidence in the estimation results.
An estimator is asymptotically unbiased if the bias approaches zero with the number of data tending to infinity. It is reasonable that as the number of data increases the estimate tends to the true value; this is a property called ‘‘consistency.’’ It is a stronger property than asymptotic unbiasedness because it has to be satisfied for every single realization of estimates. All the consistent estimates are unbiased asymptotically. This convergence is required to be with probability 1 (one):
lim P{|b(zi, Z2,…, zn) — b < 5} = 1; 8 5 > 0
Nn
The probability that the error in estimates (with respect to the true values) is less than a certain small positive value is one.
The random variable x2 given by x2 = x + x2 + ••• + хП, where x; are the normally distributed variables with zero mean and unit variance, has the PDF (probability density function) with n degrees of freedom: p(x2) = 2~n/2r(n/2)~1(x2)2~1 exp(-X2/2). Г(п/2) is Euler’s gamma function, and E(x2) = n; s2(x2) = 2n. In the limit the x2 distribution approaches the Gaussian distribution with mean n and variance 2n. Once the probability density function is numerically computed from the random data, the x2 test is used to determine if the computed probability density function is Gaussian.
For normally distributed and mutually uncorrelated variables x;, with mean mt and with variance s;, the normalized sum of squares is formed as s = ^ni=1 (xi ~m;) . Then, s obeys the x2 distribution with n DOF. The x2 test is used for hypothesis testing.
B6 CONFIDENCE INTERVAL AND LEVELS
A confidence interval for a parameter is an interval constructed from empirical data, and the probability that the interval contains the true value of the parameter can be specified. The confidence level of the interval is the chance that this interval (that will result once data are collected) will contain the parameter. In estimation result, requirement of high confidence in the estimated parameters or states is imperative. This information is available from the estimation-process results. A statistical approach is used to define the confidence interval within which the true parameters/ states are assumed to lie with 95% of confidence. This signifies a high value of probability with which the truth lies within the upper and lower confidence intervals. If P{l < b < u} = a, then a is the probability that b lies in the interval (l, u). The
probability that the true value, b, is between I (the lower bound) and u (the upper bound) is “a.” As the interval becomes smaller and smaller, the estimated value b is regarded more confidently as the true parameter.
Bayes’ Theorem defines the conditional probability, the probability of the event A, given the event B: P(A/B) P(B) = P(B/A) P(A). Here, P(A) and P(B) are the unconditional, or a priori, probabilities of events A and B, respectively. This is a fundamental theorem in probability theory. Bayes’ theorem allows new information to be used to update the conditional probability of an event. It refers to repeatable measurements (as is done in the frequency-based interpretation of probability), and the interpretation of data can be described by Bayes’ theorem. In that case A is a hypothesis and B is the experimental data. The meanings of various terms are (1) P(AB) is the degree of belief in the hypothesis A, after the experiment that produced data B, (2) P(A) is the prior probability of A being true, (3) P(BA) is the ordinary likelihood function used also by non-Bayesians believers, and P(B) is the prior probability of obtaining data B.
B4 CENTRAL LIMIT PROPERTY
Let a collection of random variables, which are distributed individually according to some different probability distributions, be represented as z = x1 + x2 + ••• + xn; then the central limit theorem states that the random variable z is approximately Gaussian (normally) distributed if n n and z has finite expectation and variance. This property allows a general assumption that noise processes are Gaussian, since we can say that these processes have arisen due to the sum of individual processes with different distributions.